

Содержание

Результаты поисковой выдачи иногда способны неприятно удивить сайтовладельца. Дубликаты, тестовые страницы и что самое страшное — конфиденциальная информация.
Например, список пользователей SMS компании Мегафон стал всеобщим достоянием в 2011 году. Причина — робот поисковика добросовестно проиндексировал все доступные страницы.
Корректная настройка файла robots.txt поможет установить диалог с ботом и рассказать ему о том, что можно индексировать, а что нет.
Назначение, принцип действия, основная функция robots.txt
Назначение файла — передача параметров индексирования сайта роботам поисковых систем.
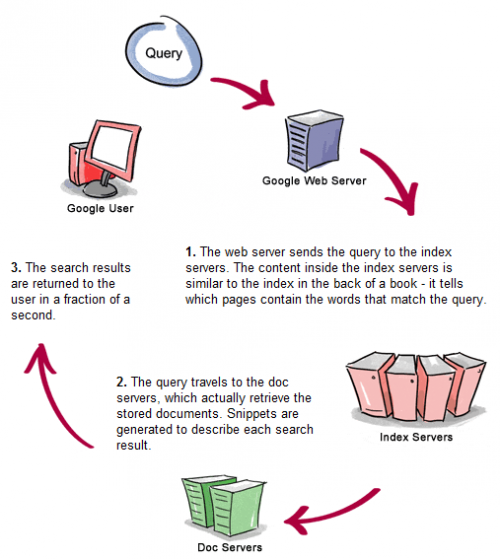
Принцип действия robots.txt заключается в следующем. Поисковый робот (другие названия: «бот», «crawler», «краулер») посылает запрос на наличие в корневом каталоге сайта файла robots.txt. При получении отрицательного ответа (HTTP-статус отличен от 200 OK) краулер индексирует весь сайтцеликом. В противном случае — считывает файл robots.txt и интерпретирует его команды.
Требования к файлу robots.txt.
- Формат — текстовый. Не допускается использование бинарных, html и прочих форматов данных. Создать файл можно с помощью текстовых редакторов NotePad (Блокнот), AkelPad и т.д.
- Размещение — обязательно корневой каталог сайта. Все прочие каталоги сайта не сканируются поисковыми роботами на наличие этого файла. Для сайта www.mysitik.net файл с url http://www.mysitik.net/robots.txt будет прочитан краулером, а файл с url http://www.mysitik.net/pages/robots.txt — проигнорирован.
- Имя файла обязательно набирается в нижнем регистре — «robots.txt».
- Максимальный размер файла — 32К. Поисковые роботы игнорируют файлы больших размеров.
Основная функция robots.txt — не допустить индексирование поисковыми роботами заданных в файле областей сайта (исключить их из индекса). По этой причине robots.txt иногда называют «Robots Exclusion Protocol», что в переводе означает «протокол исключений». Ботами этот файл воспринимается как стандарт, хотя официальным стандартом не является.
Настройка robots.txt
Структура данных файла
Записи файла robots.txt состоят из директив и комментариев.
Директивы (основные и дополнительные) — это команды, которые интерпретирует поисковый робот. Основные директивы «понимают» все роботы, дополнительные директивы могут интерпретировать только некоторые из них.
Комментарии не интерпретируются поисковыми роботами. Размещать их желательно в отдельной строке, а не в строке с директивой.
Боты старых версий могут неверно интерпретировать строку с директивой и комментарием.
Основные директивы
User-agent и Disallow — это основные директивы robots.
Директива User-agent с параметром [имя] служит началом секции (блока) команд для определенного бота или группы ботов, с параметром «*» — для всех возможных поисковых ботов. Разделителем блоков является пустая строка, наличие которой обязательно.
#секция Яндекс-краулеров
User-agent: Yandex
#секция основного Гугл-краулера
User-agent: Googlebot
#секция всех прочих краулеров
User-agent: *
Анализируя файл robots.txt краулер выбирает секцию команд с наиболее подходящей ему директивой User-agent, а остальные блоки игнорирует.
 Поисковые системы имеют большое количество ботов. Скажем, за индексацию картинок у Яндекса и Гугла «отвечают» соответственно YandexImages и Googlebot-Image, а за индексацию мультимедийной информации — YandexMedia и Googlebot-Video. При необходимости указать директивы конкретным ботам можно воспользоваться списком ботов Яндекса и списком ботов Гугла. Информацию о ботах всегда можно получить на сайтах поисковых систем.
Поисковые системы имеют большое количество ботов. Скажем, за индексацию картинок у Яндекса и Гугла «отвечают» соответственно YandexImages и Googlebot-Image, а за индексацию мультимедийной информации — YandexMedia и Googlebot-Video. При необходимости указать директивы конкретным ботам можно воспользоваться списком ботов Яндекса и списком ботов Гугла. Информацию о ботах всегда можно получить на сайтах поисковых систем.
В каждом блоке команд обязательно присутствует директива Disallow (хотя бы одна). Директива Disallow указывает на область сайта, которую запрещено индексировать. Символ «/» в терминологии Линукс означает «корневой» каталог.
Поэтому директива Disallow с параметром «/» запрещает индексировать весь сайт целиком — «от корня». Пустая, без параметра, директива Disallow выдает разрешение на индексирование всего содержимого сайта.
#секция Яндекс-краулеров
User-agent: Yandex
#разрешаем индексировать весь контент
Disallow:
#секция основного Гугл-краулера
User-agent: Googlebot
#запрещаем индексировать весь контент
Disallow: /
#секция всех прочих краулеров
User-agent: *
#запрещаем индексировать каталоги myphotos, mydocuments, а также файлы myownfile.html и testfile.html
Disallow: /myphotos/
Disallow: /mydocuments/
Disallow: /myownfile.html
Disallow: /tesfile.html
Значения параметров директивы Disallow рекомендуется набирать в нижнем регистре. Каталоги myphotos и MyPhotos — разные каталоги, а файлы myownfile.html и MyOwnfile.html — разные файлы.
Использование нескольких параметров в одной директиве является недопустимым. Если мы запрещаем индексацию файлов myownfile.html и testfile.html, нельзя использовать конструкцию
Disallow: /myownfile.html /testfile.html
Для каждого файла требуется отдельная запись с Disallow, как в приведенном выше примере.
В параметрах директивы Disallow нельзя использовать регулярные выражения, что создает определенные неудобства. Если требуется запретить индексацию большого количества файлов, мы рискуем получить файл robots.txt недопустимого размера. Такие файлы лучше переместить в отдельный каталог и применить к нему директиву Disallow.
Внешняя оптимизация — это процесс стремительного роста ссылочной массы.
Клонирование ссылочного профиля конкурентов способствует быстрому продвижению, читай здесь, как правильно это сделать.
Как повысить показатели ТИЦ и PR, вы можете узнать в нашей статье.
Дополнительные директивы
Некоторые поисковые системы предоставляют вебмастерам дополнительные директивы для управления индексацией. С подробностями можно ознакомиться на сайтах этих поисковиков. Мы остановимся на самых популярных — Яндексе и Гугле.
Дополнительная директива Allow, которую «понимают» поисковые боты Яндекса и Гугла, разрешает индексирование области сайта. В параметрах директив Allow и Disallow допускается использование регулярных выражений.
#Пример использования Allow в связке с Disallow
User-agent: Yandex
#В закрытом для индексации каталоге private
Disallow: /private/
#разрешаем индексацию только одного файла globalfile.php
Allow: /private/globalfile.php
#Пример использования регулярных выражений
User-agent: Googlebot
#В открытом для индексации каталоге books
Allow: /books/
#запрещаем индексацию файлов с расширением .php
Disallow: /books/*.php$
Символ «$» в регулярном выражении означает окончание ссылки.
Дополнительная директива Sitemap — указание местоположения карты сайта, также «понятна» обоим поисковикам.
User-agent: Googlebot
#весь контент сайта доступен для индексации
Disallow:
#карта сайта находится в корневом каталоге
Sitemap: http://www.mysitik.net/mysitemap.xml
При большом количестве страниц карта сайта разбивается на части.
User-agent: Yandex
#весь контент сайта доступен для индексации
Disallow:
#3 части карты сайта находятся в корневом каталоге
Sitemap: http://www.mysitik.net/mysitemap_part1.xml
Sitemap: http://www.mysitik.net/ mysitemap_part2.xml
Sitemap: http://www.mysitik.net/ mysitemap_part3.xml
Дополнительная директива Host поддерживается исключительно Яндексом и позволяет сообщить боту url главного зеркала сайта. Например, сайт mysitik доступен по адресам www.mysitik.net и mysitik.net. Поисковик идентифицирует их как два разных сайта с идентичным контентом.
Если на страницу mypage.htm есть ссылки с www и без него, в поисковой выдаче вес страницы разделится между этими сайтами. После назначения www.mysitik.net главным зеркалом сайта, страница mypage.htm считается принадлежащей только ему, ее вес увеличивается, и она занимает в поисковой выдаче более высокую позицию.
User-agent: Yandex
#весь контент сайта доступен для индексации
Disallow:
#главное зеркало сайта
Host: www.mysitik.net
Конфигурирование robots обязательно рекомендуется завершать проверкой его валидности. Для этой цели можно использовать валидатор Яндекса или другие подобные ресурсы.
Поделитесь с друзьями:
Просмотров: 3029 Маркетинг
Автор: Александр Мишустин, Vertex seo



















Комментарии